
Agentic Vision in Gemini 3 Flash
Google annuncia l'introduzione di Agentic Vision in Gemini 3 Flash e trasforma l’analisi delle immagini. In pratica, il modello non si limita più a guardare un’immagine una volta sola e a rispondere: ora può pianificare da solo dove zoomare, quali porzioni ritagliare, che calcoli eseguire e come annotare visivamente ciò che vede, prima di arrivare a una conclusione.
Questo approccio è pensato per risolvere un limite strutturale dei modelli di visione tradizionali. Un modello classico osserva l’immagine in un’unica passata; se manca un dettaglio sottile – come un numero di serie su un componente o un’informazione piccola in un grafico – è costretto a indovinare. Il modello deve comunque generare una risposta a partire da un contesto visivo incompleto, con il rischio di errori o allucinazioni.
Con Agentic Vision, Gemini 3 Flash può invece costruire un piccolo “piano di lavoro” sul contenuto visivo, eseguire codice Python per manipolare e analizzare le immagini e riportare nel proprio contesto i risultati di questi passaggi. Secondo Google DeepMind, abilitare la code execution con Gemini 3 Flash porta un miglioramento di qualità del 5-10% sui principali benchmark di visione (fonte: Google DeepMind, gennaio 2026). Il dato arriva direttamente dall’annuncio ufficiale pubblicato sul blog di Google.
COME FUNZIONA AGENTIC VISION IN GEMINI 3 FLASH
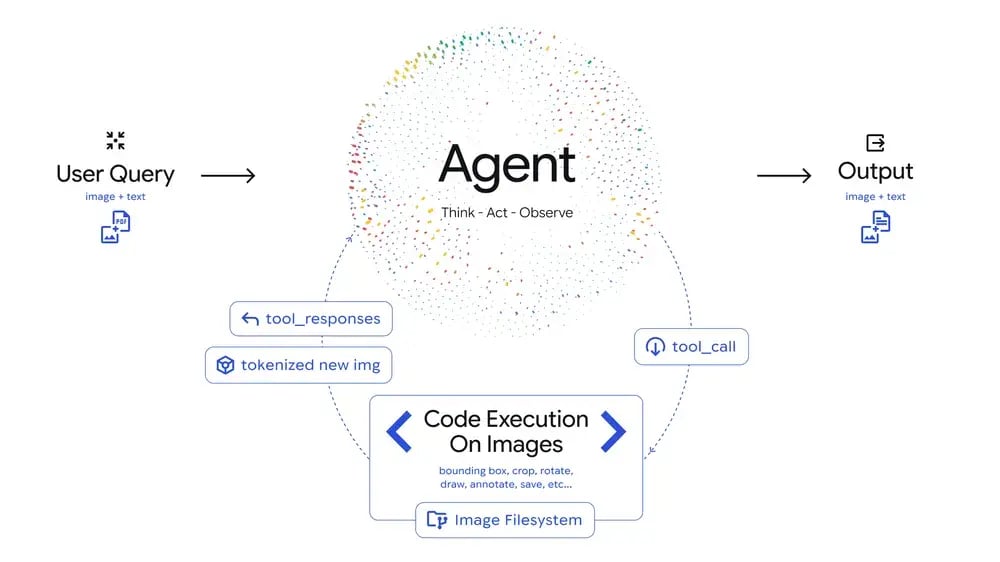
Il cuore dell’annuncio è l’introduzione del loop “Think – Act – Observe” nelle attività di visione di Gemini 3 Flash. Il modello non tratta più l’immagine come un input statico da elaborare in un unico passo, ma come un contesto da esplorare attivamente attraverso più azioni successive. Gemini 3 Flas esegue una sequenza di operazioni sull’immagine e sulle sue trasformazioni per arrivare a una risposta più solida.
Nel passaggio “Think”, il modello analizza la domanda dell’utente e l’immagine iniziale e formula un piano multi-step. Questo piano specifica, ad esempio, che cosa conviene fare: zoomare su una certa area, ritagliare un dettaglio, contare degli oggetti, trasformare dei valori presenti in un grafico. In questa fase, il modello definisce un insieme di azioni che dovranno essere applicate a regioni o componenti dell’immagine per raccogliere informazioni aggiuntive.
Nel passaggio “Act”, entra in gioco la code execution. Gemini 3 Flash può generare e poi eseguire codice Python come strumento integrato. Questo codice permette di manipolare concretamente le immagini: ritagli, rotazioni, annotazioni con riquadri e etichette, conteggi di elementi, operazioni matematiche su dati estratti. Gemini 3 Flash utilizza Python per trasformare l’immagine di partenza in nuove versioni arricchite, che contengono esattamente i dettagli che servono per rispondere.
Google mostra tre esempi emblematici di questi comportamenti:
- Zooming e ispezione iterativa
Per dettagli minimi, come numeri molto piccoli o elementi lontani in una foto, Gemini 3 Flash è addestrato a “zoomare” implicitamente quando è abilitata la code execution. Nell’esempio di PlanCheckSolver.com, una piattaforma di validazione di piani edilizi, il modello genera codice per ritagliare porzioni specifiche di planimetrie ad alta risoluzione (come bordi del tetto o sezioni di edificio) e le analizza come nuove immagini. Secondo l’articolo, questa capacità ha portato a un miglioramento di accuratezza del 5% nei controlli automatici sui progetti (fonte: Google DeepMind, gennaio 2026). - Annotazione visiva
Agentic Vision non si limita a descrivere a parole ciò che vede, ma può “disegnare” sull’immagine tramite codice. In un esempio, il modello deve contare le dita di una mano. Per evitare errori, genera codice Python che disegna bounding box e numeri sopra ciascun dito. Gemini 3 Flash crea un “taccuino visivo” annotando direttamente la scena, così che la risposta finale sia basata su un conteggio verificabile. - Visual math e plotting
Per tabelle dense o grafici complessi, l’articolo spiega che Agentic Vision può identificare i dati grezzi all’interno dell’immagine, scrivere codice per normalizzarli e produrre un nuovo grafico con strumenti come Matplotlib. In questo scenario, il modello traduce l’immagine in un insieme strutturato di dati e visualizzazioni, riducendo il rischio di allucinazioni nei passaggi aritmetici.
Dopo ogni azione, si entra nella fase “Observe”: le immagini trasformate, con ritagli e annotazioni, vengono aggiunte al contesto di Gemini 3 Flash. Il modello le “riguarda” e aggiorna la propria comprensione della scena prima di formulare la risposta testuale definitiva. Questo ciclo “Think – Act – Observe” converte la visione da atto statico a processo iterativo basato su evidenze.
Infine, Google dichiara che l’abilitazione di code execution con Gemini 3 Flash porta un miglioramento consistente del 5-10% sui benchmark di visione (fonte: Google DeepMind, gennaio 2026). Il dato si riferisce a test standardizzati nel campo della visione artificiale e segnala che l’uso sistematico di strumenti espliciti (zoom, annotazioni, calcoli) aiuta il modello a ridurre gli errori rispetto a un approccio puramente “end-to-end”.
ROADMAP ANNUNCIATA
Limiti attuali delle capacità implicite
Google chiarisce che non tutte le capacità di Agentic Vision sono ancora completamente implicite. Oggi, Gemini 3 Flash è addestrato a zoomare automaticamente su dettagli minuti quando ha senso farlo, ma altre azioni – come ruotare immagini o svolgere attività di visual math – spesso richiedono ancora un’indicazione esplicita nel prompt per attivarsi. Il soggetto (Google) riconosce che alcune capacità restano su base esplicita, con l’obiettivo dichiarato di renderle più automatiche in futuro.
Roadmap annunciata
La roadmap annunciata per Agentic Vision si articola in tre direzioni principali. La prima riguarda l’aumento dei comportamenti impliciti guidati dal codice: Google sta lavorando perché sempre più trasformazioni visive, come rotazioni, correzioni e calcoli su dati estratti, vengano attivate automaticamente dal modello quando la situazione lo richiede, senza che lo sviluppatore debba specificarlo ogni volta nel prompt.
La seconda direzione è l’introduzione di più strumenti a disposizione del modello. Oltre al codice, la roadmap include l’esplorazione di strumenti come il web search e la reverse image search, con l’obiettivo di permettere a Gemini di ancorare ancora di più la propria comprensione del mondo a fonti esterne, combinando ciò che vede nell’immagine con ciò che recupera online.
La terza direzione riguarda l’estensione a più dimensioni di modello oltre a Flash. Al momento dell’annuncio, Agentic Vision è legata a Gemini 3 Flash, ma Google dichiara l’intenzione di estendere questa capability anche ad altri “tagli” di modello, così che l’ecosistema Gemini offra visione agentica su una gamma più ampia di opzioni, sia per casi d’uso leggeri sia per scenari più complessi.
Disponibilità e modalità di accesso
Agentic Vision è disponibile tramite Gemini API in Google AI Studio e in Vertex AI. È anche in fase di roll-out nell’app Gemini, dove può essere attivata selezionando l’opzione “Thinking” dal menu del modello e abilitando “Code Execution” nella sezione Tools. In questo modo, il soggetto (sviluppatore) può sperimentare Agentic Vision in modo guidato all’interno di AI Studio prima di integrarla in applicazioni più strutturate.
FAQ
-
Che cosa significa esattamente “Agentic Vision”? Significa che il modello tratta la visione come un processo attivo: pianifica i passi, esegue codice per manipolare e analizzare le immagini, osserva i risultati e poi risponde, invece di limitarsi a un’unica elaborazione statica.
- Di quanto migliora la qualità rispetto a prima? Secondo Google DeepMind, abilitare la code execution con Gemini 3 Flash porta un miglioramento del 5-10% sui principali benchmark di visione (fonte: Google DeepMind, gennaio 2026), grazie all’uso sistematico di zoom, annotazioni e calcoli espliciti.
- Agentic Vision funziona solo con il modello Flash? Al momento dell’annuncio, la capability è disponibile con Gemini 3 Flash. Nella roadmap, Google indica l’intenzione di estendere Agentic Vision ad altre dimensioni di modello, ma non fornisce ancora date precise (fonte: Google AI, gennaio 2026).
- Quali sono gli esempi pratici mostrati nell’articolo ufficiale? Google mostra tre categorie di esempi: zoom progressivi su dettagli fini (come planimetrie con PlanCheckSolver.com), annotazioni visive su immagini (es. dita di una mano) e visual math con tabelle e grafici trasformati tramite codice Python.
- Come si inizia a usare Agentic Vision in pratica? Agentic Vision è accessibile tramite Gemini API in Google AI Studio e Vertex AI. È anche in rollout nell’app Gemini, dove si attiva selezionando “Thinking” come modello e abilitando “Code Execution” nella sezione Tools (fonte: Google AI, gennaio 2026).
